Long time no see! I have a looooooot of projects in mind and a lot far too big (+40h of work & personal community stuff & life). However, I got a list of projects I can do in one week-end(ish) (e.g. a Gartic Phone with DALL-E, play with open push, etc) and because I answer to a lot of tickets every-day, I was wondering how this can be automatized nowadays with all the new AI projects (for the fun, to be honest, I think a good FAQ should answer to all common questions and a good documentation should complete this. So, you just have to fix bugs and redirect to the FAQ/doc).
So, I took a few hours to play with GPT-3 during a week-end (I had an access for two months without using it) to create a small bot that will answer my tickets. This bot is called: GePeTTTo.
Do not think too big
Because I have a life and other priorities (learn things to my cat, cook, talk with friends, etc). I really need to scope my projects more than ever (yeah I’m not a student anymore).
So, the goal of this project is to get in one week-end a small CLI application which:
- Get latest GitLab tickets
- Can inject issues from a URL or a file (make it easy to debug for me if there is no new issue).
- Generate answers to those tickets with a custom model.
- Be able to save or send the answers. I could be automated, but to be honest, except hosting yet another bot, it’s not necessary.
And I need to do:
- Play with the GitLab’s API to retrieve projects/issues/discussions and post new comments
- Retrieve all my comments to train a custom model
- Play with OpenAI’s API to train a model and generate answer
- Create a small Python app to make it usable
- Fix the bugs, publish the code
- Write an article, because I do stuff but I don’t write much.
Playing with GitLab
GitLab is a HUGE project, with a huge API, but the documentation is good.
The first step is to get an access token via https://INSTANCE_GITLAB/-/profile/personal_access_tokens once logged with the api and read_api permissions.
Then, we can read the documentation. In my case:
https://docs.gitlab.com/ee/api/issues.html https://docs.gitlab.com/ee/api/discussions.html https://docs.gitlab.com/ee/api/projects.html
Then, the simplest way to know what we will have to parse is to use that good old curl:
# Retrieve all projects from an instance (here gitlab.com)
curl https://gitlab.com/api/v4/projects
# Or to post a comment in the issue #42 in project 42
curl -XPOST --header "PRIVATE-TOKEN:tres_tres_prive" "https://gitlab.com/api/v4/projects/42/issues/42/notes?body=foobar"
In the final script, I use requests
A small example:
def answer(self, project_id, issue_id, body):
endpoint = f'{self.git_url}/api/v4/projects/{project_id}/issues/{issue_id}/notes?body={body}'
response = requests.post(endpoint, headers=self.headers)
if 'error' in response.json():
print(f'An error occurred while posting to {endpoint}')
else:
print(f'Answered to issue {issue_id} with success')
Playing with OpenAI
Get a token
The API is documented there: https://openai.com/api/
And the first step is to generate a key (after getting access to the beta) here: https://beta.openai.com/account/api-keys
Play a little
A lot of demonstrations are available here and even a playground here!
So, let’s try to answer to a post from StackOverflow https://stackoverflow.com/questions/73311716/gpt3-point-as-terminator-of-sentence:

which is similar to the use-case I want. The only thing to do is to start with “Answer to this”, else GPT-3 will just complete the text (with something like “Thanks, Pierre”).
A minimalist interface
Minimalist, but usable
To create the CLI interface I’ll use cmd, which is an easy to use Python’s module that can handle the input (go to the previous command Ctrl+W, Ctrl+U, etc.) and it’s easy to add new commands, for example:
def do_save(self, arg):
filename = arg if arg != '' else f'{self.answeringTo["id"]}.answer'
with open(filename, 'w+') as f:
f.write(self.answer)
This code adds in a few lines a save command (to save a file passed in the arguments or a generated one), or another example with the help command:
def do_help(self, args=''):
print('start: Start to analyze issues')
print('save <file>: Save generated answer to <file>')
print('send: Send answer without saving it')
print('send <file>: Send answer from file')
print('add <url>: Add an issue from an url')
print('add <file>: Add an issue from a file (no send possible)')
print('next: Pass to the next issue')
print('exit: Close GePeTTTo')
Then it’s possible to show text in a wanted color with:
print(colored('text', 'green'))
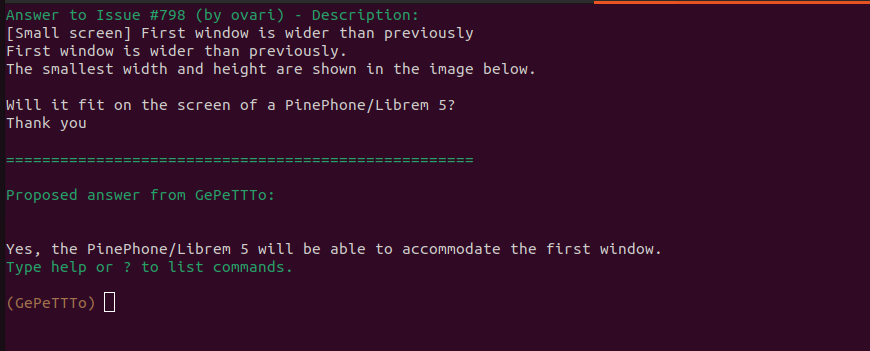
Some screenshots
Now that everything is plugged, this is what it looks like:

Train a custom model
Now that the script do what I want, the next step is to try to get better answers. For that, I need to customize a model, and I found this article: Customizing GPT-3 for Your Application which explains what I want.
At first, I tried to parse the whole GitLab instance to get all the comments I posted. It generated a models with a few thousands inputs after filtering a lot of “this is a duplicate of…”, “non reproducible”, “fixed, close” because I don’t want the bot to generate this. The inputs looked like:
{ "prompt": "Answer to this:\n<comment>", "completion": "<my_answer>###"}
{ "prompt": "Answer to this:\n<comment2>", "completion": "<my_answer2>###"}
...
and I can train a custom model via the following command:
openai api fine_tunes.create -m davinci --n_epochs 2 -t myfile
This generates a custom model I can use in Python with:
openai.Completion.create(\
model="davinci:ft-personal-2022-00-00-00-00-00",\
prompt=f"Answer to this issue:\n\n{json.dumps(issue['body'])}",\
temperature=0, max_tokens=500\
)
However:
- A lot of answers were nonsense and a lot of garbage.
- A lot of bad characters were generated inside the answer.
- Sadly, whatever I was generating, the answer has a length of max_token (so around 500 words), but not with
text-davinci-002.
I thought that the first point was because of my filtering in the training data. There are a lot of backtraces, logs, some code sometimes, noise and the best tickets were tickets asking questions, not about how to reproduce a bug. So, Option A - I needed to sort the current data again to keep the best lines. Or Option B - I restart from scratch and write a new model with a FAQ and some answers I mainly wrote (and that I can also use the question label on the GitLab I use).
Once this garbage problem handled, I checked the weird characters issues. The reason is that a lot of my training data contained some Markdown input. So, I needed to remove the format and use a plain/text (I converted the Markdown to plain/text in Python directly with markdown and BeautifulSoup).
Finally, the third point took me some time to figure out. I tried different inputs with and without the end mark (I changed it to <END>) before solving it. The OpenAI’s API take a stop parameter:
openai.Completion.create(\
model="davinci:ft-personal-2022-00-00-00-00-00",\
prompt=f"Answer to this issue:\n\n{json.dumps(issue['body'])}",\
temperature=0, max_tokens=500\
stop="<END>"
)
Et voilà!
Deploy it!
The project
All the sources for this project is there (and should be usable): https://github.com/AmarOk1412/GePeTTTo
Some examples
Some examples in another language (French)
Because I also check a lot https://zestedesavoir.com (a French Forum), I was wondering if I can use the exact same code for answering to French tickets. And this is 3 examples I generated (if you understand French):
- Answer to https://zestedesavoir.com/forums/sujet/16395/charger-ordinateur-avec-thunderbolt-ou-port-natif/
Oui, vous pouvez recharger votre ordinateur portable Thunderbolt 4 via le port USB sans rien configurer. Cependant, il est recommandé d’utiliser le chargeur natif pour une meilleure performance.
- https://zestedesavoir.com/forums/sujet/16355/probleme-performances-chrome/ (answer to the first post)
Il y a plusieurs raisons qui pourraient expliquer les performances de Chrome. Il se peut que vous ayez trop d’onglets ouverts, ce qui ralentit votre ordinateur. Vous pouvez également avoir des extensions ou des programmes en cours d’exécution qui utilisent beaucoup de mémoire et de CPU.
Il existe plusieurs façons de résoudre ce problème. Vous pouvez d’abord essayer de fermer quelques onglets ou de désactiver temporairement les extensions que vous n’utilisez pas. Vous pouvez également vider le cache et les cookies de Chrome pour voir si cela améliore les performances.
- And a custom test about TURN/Jitsi:
Moi: Répond à ceci:
“Bonjour, J’essaye d’héberger chez moi une instance de Jitsi. Cependant, je ne comprends pas tous les parametres notament useTurnUdp. Qu’est-ce qu’un serveur TURN et pourquoi est-ce désactivé par défaut? "
GPT-3: Bonjour,
Un serveur TURN est un serveur qui peut être utilisé pour relayer des flux audio et vidéo en cas de besoin. Il est désactivé par défaut car il n’est pas toujours nécessaire, mais peut être activé si vous rencontrez des problèmes de connectivité.
Moi: “Quel genre de problème de connectivité ?”
GPT-3: Les problèmes de connectivité peuvent être dus à des blocages de pare-feu, à des connexions instables ou à d’autres facteurs. Le serveur TURN peut aider à contourner ces problèmes en relayant les flux audio et vidéo directement entre les participants, sans passer par le réseau.

To conclude this weekend (in fact, it took me 2 more days) of experimentation, it works well so far. There are still some limits, failed answers, but a lot of answers are good and I really think behind GPT-3 there is a lot of HUUUUUUUUUUUGE datasets. Like DALL-E 2, my tests in other languages seem to work and the whole project was pretty easy to do.
However, it’s still a beta. Sometimes the documentation is not perfect, a lot of models can’t be customized (text-davinci-002 for example). Also, like a lot of AI projects, the difficult point (and most consuming) is to create a good dataset to train the model you want to use and avoid any weird formatting (except if you want to generate code).
See ya!