In the previous articles we talked about how to create a peer to peer connection and what issues we can encounter. These problems are generally due to the NAT which needs methods to pass through it (e.g. TURN servers) or some new protocols (like ICE).
It is now time to talk about distributed applications and structures created on top of a p2p network.
For a lot of distributed applications, all the nodes in the system can’t be stable. In fact, nodes continuously join and leave the network for a lot of reasons. So, we need to use a structure which connects all the nodes of the network to maximize the coverage of that network (we don’t want to have nodes in a sub-net) and to get the best response time.
In this post, I will introduce a distributed structure which meets this need and which is used a lot in p2p applications: the DHT (Distributed Hash Table).
What is a DHT?
A DHT is a hash table (it’s in the name!) but stored on a set of nodes (where each node store a part of the DHT) on several devices. This technology was democratized by a well-known software: BitTorrent.
In a DHT, the value of the hash function gives the peer hosting the data. The two main algorithms are Kademlia and Chord. In this post I will talk about Kademlia.
Also, a DHT has two other characteristics:
- Unlike a blockchain (maybe I will talk about it in another post) there is no authority. There is no need to trust the network.
- The storage is not persistant. Generally, each data have a time to live.
And how it works?
Let’s imagine a cluster of nodes around the world. Without any logic, we can’t really ask every node to connect to some other nodes without the certitude to get an interconnected network where each node can talk to any other one. We have to create some sort of spatial scheduling. Let’s say that each node has a random identifier (a hash). So the order will be (00000, 00001, …, 11111) and we can imagine a circle like the following image:
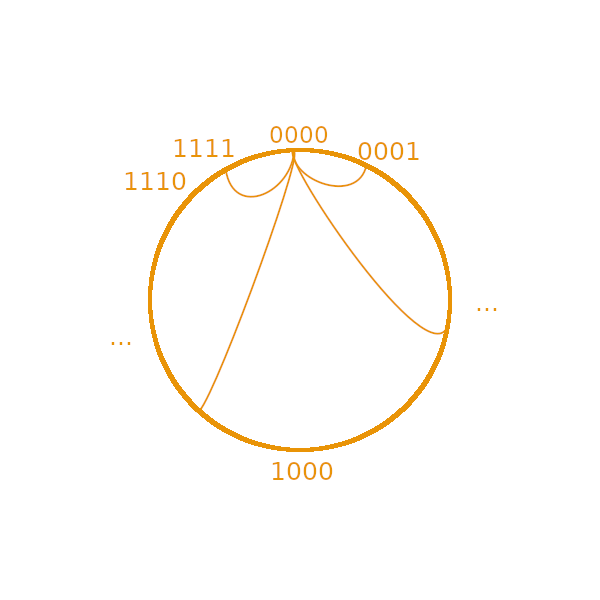
If we have a circle of N nodes, we can interconnect the nodes by connecting a node to one neighbor. With this technique, the number of connections in that network will be minimized (N for all of the network), but the time to send a message will be maximized. On the contrary, we can also connect a node to all of the peers. We will have a lot of connections (NxN) but we will minimize the time to send a message. But other techniques exist, to get a quick transmission without many connections (and still easy to calculate).
On a Kademlia like network, each node has a 160 bits random identifier (and the hashes keys have the same length). To define the distance between two nodes, the XOR method is used. Thus, the nodes …0101010 and …0100010 will have a distance of …0001000.
Storage
Let’s imagine that Alice wants to store a value on the DHT: hash(foo) = bar. hash(foo) is a 160 bits long key. We can find the node that will store the data bar in a complexity like O(log(N) + Ω). However, because this node can leave the network during the next seconds, the data must be stored in a redundant way. So, the data will be stored in the k nearest nodes to guaranty a time to live. For example, IPFS defines k=20 (to confirm) and BitTorrent k=8 (to guaranty a ~10 minutes ttl).
Routing
Each node in the DHT divides the cluster in buckets until having one bucket with k nodes present (including the current one). The routing table for F (id=10010…) will be:
| Bucket ID | Nodes |
|---|---|
| X | 0aaaa 0bbbb |
| 1 | 11aaa 11bbb |
| 10 | 101aa 101bb |
| 100 | 1000a 1000b |
| 1001 | 10011 10011 |
| … | … |
The last bucket has F.
A protocol can be defined to interact between peers. First, the insertion of nodes in the routing table is defined by:
X is a node for bucket B. If B is not full, X is added. Else, if the bucket contains expired nodes, X is added to B (and the expired node is removed) or if X is in the same bucket as F we divide B. In the other cases, we drop X.
The following operations are also defined:
- ping
- find(n) to get the list of the k nearest nodes of N.
- put(k,v)
- get(k)
Join a network
Now that the protocol is designed, we have to discuss an important step: joining a DHT network. To do that, every node in the network is a potential entry point. However, in most of the cases, we need a node that is always up and known. That node is called “the bootstrap server” and will be the entry point for new peers (e.g. router.bittorrent.com, bootstrap.jami.net, etc).
Maintenance
Because the routing table can’t be fixed (nodes are able to leave or join the network), we need to maintain some sort of synchronization with the network. Periodically, a node will try a find(F) to maintain its direct neighbors and for each bucket find(i) where i is a random identifier of B to fill the bucket (if B is empty, the identifier comes from the previous bucket) and to remove expired nodes.
Retrieve a value
Finally, if Bob wants to get the values stored for hash(foo), he has to send find(hash(foo)) on the DHT to get the k nearest nodes of hash(foo). When the list is stationary, the search operation is done.
Thus, it’s possible for all peers to get or to send a value on the resulting list via get(k) and put(k,v),
Some projects using a DHT
As we have seen, the DHT is a structure allowing to store relatively simply data on a distributed network. This kind of network can contains tens of millions of nodes with a lot of unavailable nodes (NAT, here you are) or with nodes only available for a few seconds.
Even if a DHT is slower than a classic client/server architecture (and more complex to analyze), a lot of projects (other than Bittorrent) use this technology (I will write about a lot of these projects later):
Let’s do a quick project!
Wabi is a smart city where pollution sensors are present everywhere. Every sensor is a DHT node and put collected data every minute on the network to hash(pollution_level). A data is something like:
SIGN(sensor_key,{
"lvl_percent":78,
"lat":39.010941,
"long":125.723739
})
Moreover, each inhabitant is able to connect to the distributed network of the city to follow the pollution level and to add its own sensor.
The following Python script is a little demo for this project (if you want to improve it, you are welcome). In this script, I use Opendht which is a C++ DHT implementation with Python bindings. This library has some interesting primitives like the listen(k) operation to follow a stream on a key. Moreover, the library supports cryptographic operations to send signed and encrypted values.
#!/usr/bin/env python3
# Example
# In one terminal
# python3 sensor.py
# On another
# python3 sensor.py "{\"lvl_percent\":39,\"lat\":39.093214,\"long\":125.688883}"
# python3 sensor.py "{\"lvl_percent\":39,\"lat\":39.017443,\"long\":124.7365321}"
import opendht
import asyncio
import base64, json
import sys
def listen_cb(node, v):
try:
json_object = json.loads(v.data.decode())
latitude = json_object["lat"]
longitude = json_object["long"]
lvl = json_object["lvl_percent"]
if latitude and longitude and lvl:
key = str(latitude) + "x" + str(longitude)
node.sensors_map[key] = lvl
print(f"Sensor at lat: {latitude}, long: {longitude} - pollution detected: {lvl}")
except:
print("Illegally formatted value received")
return True
class DhtNode:
def __init__(self, is_bootstrap):
self.sensors_map = {}
self.n = opendht.DhtRunner()
self.n.run(ipv4="", ipv6="", port=4242 if is_bootstrap else 2424)
if not is_bootstrap:
self.n.bootstrap("localhost", "4242")
self.key = opendht.InfoHash.get("pollution_level")
def follow_stream(self):
self.n.listen(self.key, lambda v: loop.call_soon_threadsafe(listen_cb, self, v))
loop = asyncio.get_event_loop()
loop.run_forever()
def put(self, data):
v = opendht.Value(arg.encode('utf-8'))
self.n.put(self.key, v)
if __name__ == "__main__":
node = DhtNode(len(sys.argv) == 1)
if len(sys.argv) > 1:
for arg in sys.argv[1:]:
node.put(arg)
else:
node.follow_stream()
Go further
- The Kademlia paper
- A video from Anne-Marie Kermarrec: